5 Key Strategies to Optimize Your LLM Costs
Balancing cost with performance
- Aguru

Introduction
If you’re developing or have already launched LLM-backed AI applications or agents, you’re undoubtedly aware of the substantial costs associated with deploying and operating LLM applications. Managing these costs effectively is vital for scaling your AI initiatives. Central to LLM cost management is finding the right balance between cost and performance. This guide outlines the top 5 strategies for optimizing LLM usage costs without sacrificing the quality of service.
Understanding the Costs of LLM deployment
Deploying LLMs involves various costs, from direct usage fees to indirect operational costs related to infrastructure, maintenance, and the expertise required to integrate and manage these systems. The specific expenses linked to LLM usage can vary widely, largely influenced by:
- Model size: Larger models often excel at processing complex prompts but are notably more costly.
- Amount of data processed: Costs accrue from both the prompts sent to and the outputs received from LLMs, with inputs usually incurring lower expenses than outputs.
The correlation between the larger models’ greater capabilities and their higher costs underscores the importance of strategic cost management. This entails finding a delicate balance between cost and performance. Importantly, there’s no one-size-fits-all solution for the most efficient LLM deployment; each project may need to navigate its potential trade-offs between cost and capability.
The challenges of managing LLM costs
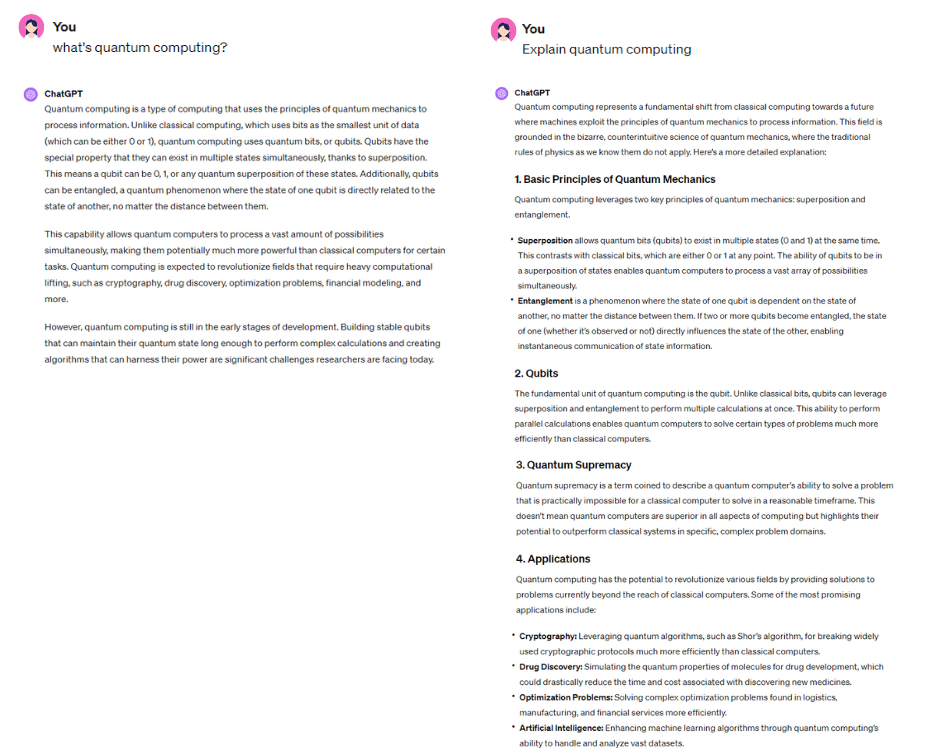
Operational costs associated with infrastructure, maintenance and the required human resources make LLM applications a significant expense within your IT stack. However, the real challenge stems from the unpredictable nature of LLMs, where minor changes in prompts can lead to large variations in response length – and, consequently, cost. For example, as illustrated below, two nearly identical prompts can differ in cost by up to 90%. This unpredictability necessitates the adoption of strategies that effectively manage usage expenses without compromising the quality of the solution.
Strategies for LLM Cost Management
Now let’s dive into the different strategies and available solutions to efficiently manage LLM costs.
1. Prompt compression
By employing algorithms to semantically condense queries, this technique ensures that LLMs receive just enough information to craft a response, significantly lowering costs. When done efficiently, this process not only reduces the input length and thus cost, but also removes noise and redundant information in the prompts, leading to more efficient output generation. A notable method in this domain is LLM Lingua, a relatively new approach introduced by Microsoft designed specifically to filter out superfluous and confusing elements in prompts before they’re sent to costly models. The goal here is to lower LLM operational costs while simultaneously enhancing the quality of the output.
2. Caching technique
Integrating a caching layer between your LLM server and AI application can be a strategic move. This setup allows the storage and reuse of LLM responses for new but semantically similar queries. It uses a combination of deterministic memorization and heuristics to decide which information should be saved for future use. This method reduces LLM costs and computational resources, while speeding up output generation. It’s especially efficient for handling recurring questions or prompts.
Aguru introduces a unique caching solution tailored to reduce costs linked to repetitive or similar queries. It also incorporates tiered usage controls, enabling caching to be applied selectively based on usage levels. This ensures high precision in outputs where necessary and allows for customization of settings, such as budget caps, transactions per minute (TPM), requests per minute (RPM), and choosing the most suitable LLM model for each tier.
3. Prompt engineering
It’s the process of efficiently designing the input (or “prompt”) to a LLM to achieve a specific desired output or behavior. This involves structures the prompt in a way that guides the model to understand and respond to the query as accurately and relevantly as possible. While the primary objective of prompt engineering centers on enhancing the quality of answers, certain prompt engineering techniques can also help mitigate LLM costs. These include:
- Use explicit instructions and example-based prompts to guide the model to generate the desired output in a single attempt.
- Develop reusable prompt templates for common tasks or queries to ensure consistency and efficiency. Templates can be fine-tuned over time for optimal performance, balancing detail and brevity.
Incorporating specific constraints and context details. - Eliminate unnecessary verbosity to reduce costs.
4. LLM model selection
The landscape of Large Language Models (LLMs) is rich and diverse, with each model bringing its own pricing structure and set of advantages and limitations. As the field continues to evolve, we expect an influx of new contenders, making the selection of the most cost-effective model without compromising on output quality a pivotal factor in minimizing LLM-related expenses. Several strategies stand out for their potential to optimize this selection process:
- LLM cascading: This strategy involves using a sequence of LLMs, organized from the least to the most resource-intensive and complex models, to process tasks or queries. This method starts by directing a given task or query to the most economical, smallest model available. If this model produces an output that meets predefined quality requirements, the process ends there, and the response is delivered to the user. Should the initial output fall short of the necessary standards, or if the task proves too complex for the model’s capabilities, the query is then escalated to the next most economical model in the hierarchy. This escalation continues stepwise through the sequence of models until a satisfactory response is generated or all available models have been attempted. Despite potentially engaging multiple models for a single task, this cascading approach typically incurs lower overall costs than defaulting to the most powerful, and consequently most expensive model from the outset. FrugalGPT is noted as one of the pioneering solutions employing the LLM cascade methodology.
- LLM routing: A technique used to distribute queries to the most cost-effective LLM model while ensuring the performance. The process usually routes user requests based on factors like query complexity, the model’s expertise area, the response latency, the output length, and the need for computational efficiency. When done efficiently, this not only optimizes the use of resources but also improves response quality and speed for end-users, enabling more tailored and effective interactions with AI applications.
- Task decomposition: Simplifying complex inquiries by dividing them into manageable subtasks allows for the utilization of smaller, more cost-effective models. This method not only aids in resource conservation but also in financial savings, as simpler models often entail lower operational costs.
5. Fine-tune smaller models with your proprietary data
Typically, larger models are known for producing higher-quality outputs and handling complex tasks more effectively. However, they also bring significant challenges, including substantial computational demands, higher costs, and longer latency. In contrast, smaller models offer better cost-effectiveness and reduced resource consumption. While they may not achieve the same performance level as their larger counterparts in every task, they can be adeptly fine-tuned to excel in specific areas without sacrificing output quality. Research by Deepmind in March 2022 highlighted this advantage, demonstrating that smaller models, when trained on extensive data, can surpass larger models trained on less data in a variety of specialized tasks. Thus, strategically fine-tuning smaller models with your own dataset for targeted applications presents an economically sound approach to integrating AI into your business operations while ensuring the quality of outcomes remains high.
Conclusion
As businesses navigate the LLM landscape, it becomes imperative to adopt a holistic approach that not only targets cost reduction but also ensures the preservation of quality and efficiency in AI-driven operations.
The strategies outlined, from prompt compression and prompt engineering to the innovative use of caching techniques, LLM model selection, and model optimization, form a comprehensive toolkit for businesses at the forefront of AI innovation. Each strategy, with its unique benefits and considerations, underscores the importance of a tailored approach that aligns with specific business needs and operational contexts.
As we look towards the future, the evolving landscape of LLMs and their application in business contexts will undoubtedly introduce new challenges and opportunities for cost management. However, with a strategic approach grounded in the principles and techniques discussed, businesses can navigate these waters with confidence, ensuring that their AI investments deliver maximum value and impact.