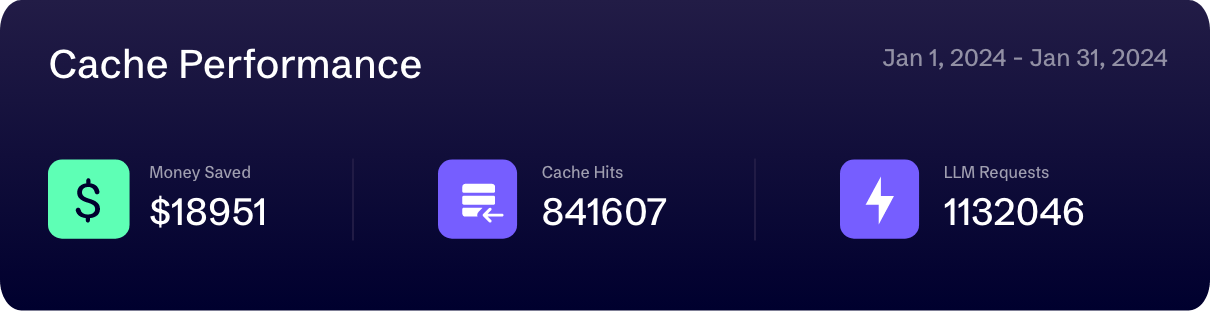
Our advanced caching technique instantly identifies and matches similar queries using semantic search. It reuses previous responses for these new, comparable prompts, delivering significant cost savings and faster response times without sacrificing quality.
CACHE INSIGHTS
Understand how Caching works for your prompts
Discover the cost savings achieved through Caching with semantic matching. Gain a detailed view of how new prompts are matched to past prompts and how cached responses are reused. This insight is available even when Caching is not activated, allowing you to observe its potential impacts on your prompts and accuracy, enabling you to make confident decisions about its application in your AI solutions.
TRY AGURU
See how our Caching solution boosts cost-efficiency for your AI applications