Unpredictable prompts and LLM responses can lead to unexpected, often substantial LLM usage bills. Simply limiting budgets may prevent abrupt spending but risk service downtimes, affecting user experience. This is where Aguru steps in. Its efficient QoS control solution helps you manage the unpredictability of LLMs, balancing costs with app performance.
SMART CACHING
Minimize LLM usage while maintaining response quality
Our smart caching technique instantly identifies semantically similar queries and reuses previous responses for these new, comparable ones, delivering significant cost savings without sacrificing response quality. For situations requiring utmost precision, you can easily opt out of semantic matching, ensuring optimal accuracy.
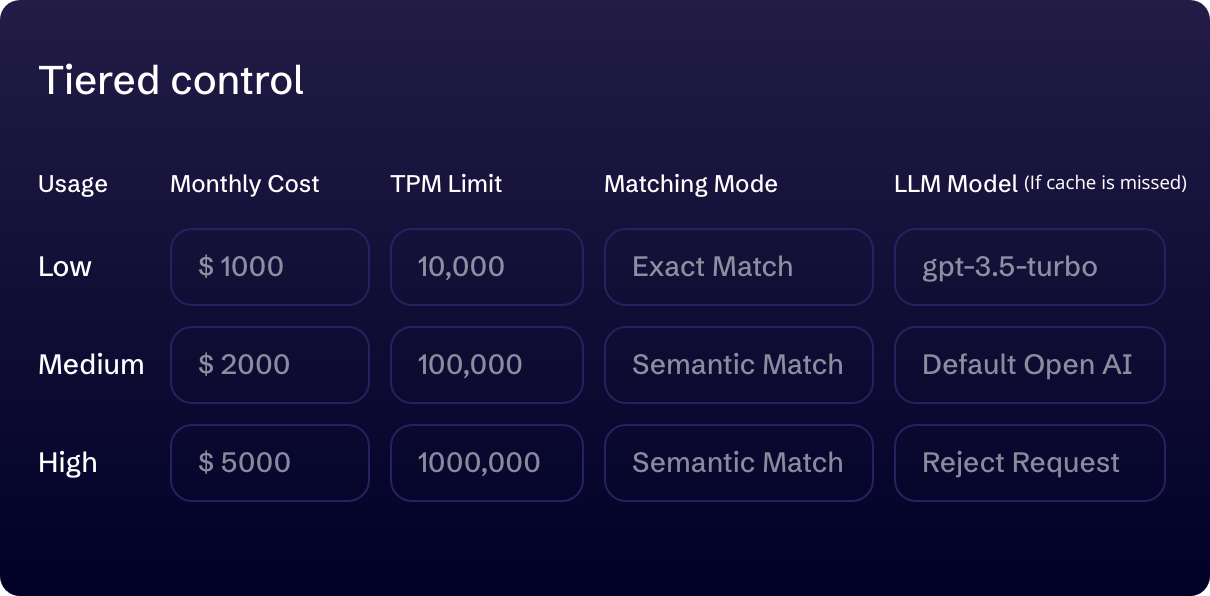
TIERED USAGE ALLOWANCE CONTROL
Balance LLM cost with app uptime
Our tiered solution is designed to gradually pace out LLM usage according to your budget and LLM capacity allowances, maximizing your AI app’s uptime and performance without exceeding budget limits. Customize budget caps, token thresholds, request limits, decide on implementing semantic matching with smart caching, and choose the optimal LLM model for each usage tier. Our system dynamically adjusts LLM usage to your specified settings, ensuring seamless transitions between tiers as thresholds are met, preventing any unexpected disruptions.
REAL-TIME ALERTS
Real-time multi-support alerts (coming soon)
Stay informed with real-time alerts via email, PagerDuty, Slack, or your chosen communication channels when usage approaches your predefined limits. This feature enables immediate action, ensuring uninterrupted service and operational consistency.
UPCOMING INNOVATIONS
More Custom QoS settings are on the way…
We’re rolling out new cost control settings to help you further enhance cost-efficiency as you scale. Be the first to experience our latest innovations.