Your tailored LLM Routing & Caching solution, powered by clustering insights
Balance performance and cost, increase speed and uptime, while gaining enhanced data visibility
OUR SOLUTIONS
Decipher, reuse, and route your prompts for optimal cost-efficiency
Ensure the profitability and scalability of your AI projects
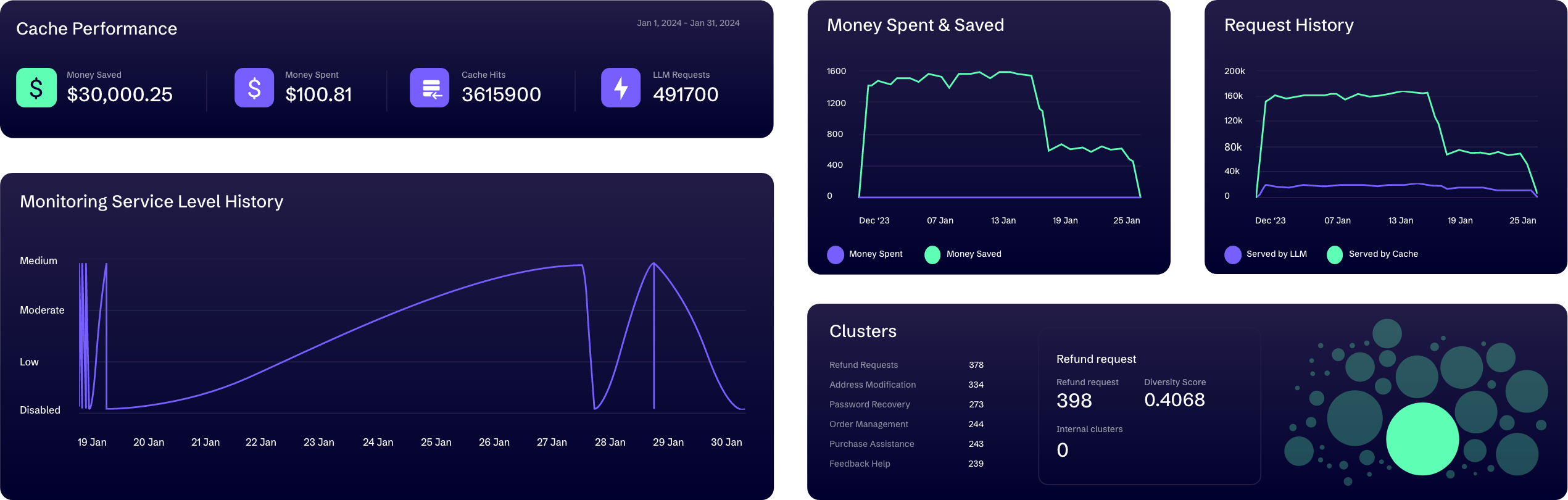
Cluster-Based LLM Router
Unlike other routers that direct your queries based on generic LLM model benchmarks, our cluster-based LLM Router assesses LLM performance and costs tailored to your unique datasets. It categorizes your specific prompts into semantically similar clusters, each representing a distinct user pattern, and evaluates various LLM models against your current LLM model on a cluster-by-cluster basis. Queries are then intelligently routed to the most suitable model based on your predefined balance between performance and cost. This customized approach ensures optimal accuracy and reliability in routing your unique queries.
Efficient LLM Caching
Alongside our LLM Router, our efficient LLM Caching solution minimizes unnecessary LLM expenses for AI applications frequently handling repetitive queries. It cleverly reuses past LLM outputs for similar, new prompts through semantic search, and allows you to define the degree of similarity between new and cached prompts, ensuring an optimal balance of quality and cost for you. This also reduces computational resources, accelerates response times, and manages throughput and requests per second (RPS) constraints.
Insightful Data Clustering & Visualization
Our Clustering functionality transforms large, unstructured data into semantically meaningful clusters, providing deep insights into your user interaction patterns. It offers a comprehensive view of your data landscape, including a distinct ‘noise’ group for semantically non-conforming data inputs. Each cluster comes with vital metrics such as cost, performance scores of each LLM model, cluster quality, and inter-cluster similarity. These intuitive yet in-depth insights facilitate rapid cost and performance assessments per cluster, and enable swift detection of outliers and anomalies for further app enhancements.
TRY AGURU
Curious about how our solution will work for your AI applications?
FAQ
Frequently Asked Questions
How do I implement Aguru?
Aguru connects to your LLM model through API, compatible with Python and node.js environments. It’s built for fast, easy implementation. Once you’ve created your trial account, you’ll see an explicit user guide that guides you through the integration in just a few clicks.
I want to see how Aguru’s LLM Router works in action before letting it automatically route my queries. Is it possible?
Of course. You have 3 options:
1. Set up a demo: We’ll schedule an online demo with you to give you a thorough walkthrough of Augur’s LLM Router, Caching, Clustering, and answer any of your questions.
2. Use observation mode: By simply deactivating LLM Router, Caching, or both, you’ll activate observation mode. This means you’ll see how your new queries are answered through cache, and/or how the answers from other LLM models compared to your original LLM, without having the feature(s) impact your new queries.
3. Use historical data: You can upload your historical dataset into Aguru to see how Aguru’s LLM Router and Caching work, instead of applying the functionality on new prompts. This feature isn’t activated in trial account by default, but can be added quickly. If you prefer this option, contact us.
How do you evaluate LLM models performance?
We use BERTScore to measure the output quality to each query. And you’ll see the different scores of different LLM models for the same query in our LLM Router, with 1 being the highest performance.
When LLM Router and Caching are both activated, what’s the workflow in Aguru upon inference?
When LLM Router and Caching are both activated, Aguru will first compare a new prompt to past ones to see if any past response can be reused. If not, it’ll pass the new query to LLM Router, routing it to a more cost-effective model based on your quality and cost tradeoff threshold. Coupling LLM Router and Caching will bring enhanced cost optimization to businesses constantly receiving semantically repetitive queries and a substantial amount of queries in general.
Can I choose to only trial one feature, either LLM Router, Caching, or Clustering?
Of course you can. All the 3 features are included in the trial, and it’s your decision which feature you want to experiment with. It only takes a click to activate or deactivate LLM Router or Caching. Clustering is set to be activated all the time, in order to provide you visibility into your user interaction with your app.
How long does the trial last?
We’re flexible with the trial length. Our primary goal is to build a solution that truly adds value to your business, so we’re flexible with the time you need to test our solution and share with us your feedback on the product and future features you’ll need.
WHO WE ARE
Our Team
Designed and built by passionate AI engineers Backed by technology business leaders

Oleg Simrnov
Product & Engineering

Derek O’Carroll
Funding Strategy, Operations & Investment

Nick Shaw
GTM Strategy & Revenue